A working paper by the Department for Promotion of Industry and Internal Trade (DPIIT) proposes a new framework to regulate how AI Large Language Models (LLMs) access online content.
- Objective: To balance the interests of Copyright Holders (publishers) and AI Developers (data consumers).
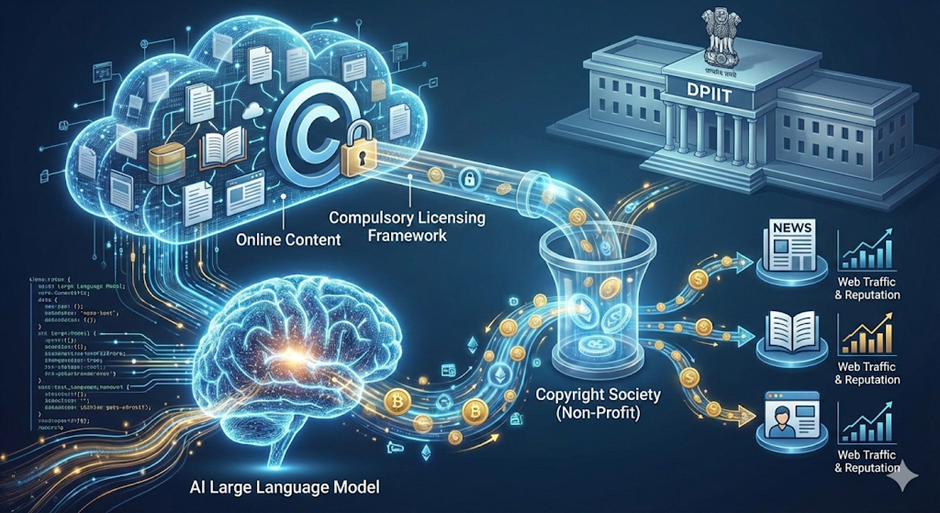
2. What is the Proposed Framework?
- Default Access: AI models should have default access to all freely available online content for training.
- No Opt-Out: Publishers/Creators should not have the right to block AI access (no opt-out mechanism).
- Reasoning: Small creators lack resources to enforce opt-outs effectively.
- Monetization Model: Implementation of a “Compulsory Licensing” style system.
- AI firms pay a statutory fee to access data.
- This eliminates the need for individual negotiations with every publisher.
3. How will Administration Work?
- Copyright Society: A non-profit body (similar to those for music rights) will be established or designated.
- Function:
- Collect royalties from AI companies.
- Distribute funds to content creators (both members and non-members).
- Distribution Criteria: Royalties to be based on metrics like web traffic and social reputation of the publisher.
Key Terminology for Prelims
- Compulsory Licensing: A mechanism under the Copyright Act, 1957, where the government allows the use of copyrighted material without the owner’s specific consent, provided a fixed royalty is paid (e.g., Radio stations playing music).
- DPIIT: The nodal department under the Ministry of Commerce and Industry responsible for IPR policy (Copyrights, Patents, Trademarks, GI).
Counter-Argument?
- Nasscom’s Dissent: The industry body argued against forced royalties, terming it a “Tax on Innovation.”
- Demands: They advocate that mining freely available (non-paywalled) data should be free, with an option for creators to “reserve” rights if they choose.